There’s no doubt that the recent launch of Google Instant has caused considerable debate within the search community. Some describe it as further evidence of Google’s ability to deploy disruptive search technologies and change the nature of how we search, and, along with it, the dynamics of whole industries such as SEO. Others see it as merely an incremental feature that will make very little difference to the way we search and may even even undermine the user experience through distracting page refreshes.
So who is right?
Before we answer that, let’s clarify exactly what we mean by Google Instant (GI). The basic idea, in case you weren’t aware, is that instead of presenting a static page of results after each query, the search results are updated in real time after every key press as the user is typing. You could think of it as an extended Auto-suggest function designed to occupy the entire result page (BTW, auto-suggest is one of the patterns recently featured in the Endeca UI Design Pattern Library). In addition, GI also predicts likely keystrokes based on the current input, analogous to the predictive text input that is so common on mobile phones. This is essentially an implementation of a design pattern known as Auto-complete, and is used by GI to indicate the default query represented by result set at any given time. But the major benefit claimed for GI is faster searches: Google estimates that Instant can save 2-5 seconds per search, which, if everyone used it globally, could save as much as 3.5 billion seconds a day.
So, given what we now know about Google Instant – will it change the way we search?
The answer is, of course, it depends. Even though opinions vary widely on the value of this feature, what they have in common is they are based on a set of implicit assumptions about the context of use, i.e. the circumstances under which the feature will be experienced. So to answer the question in a principled manner, we need first to make those assumptions explicit, and then establish exactly which aspects of the context are relevant and how they affect the search experience. In so doing, we should look beyond web search and consider the broader discovery experience and human information seeking behaviour in all its forms, i.e. encompassing web search, site search, enterprise search, and so on.
The Dimensions of Search & Discovery Experience
There are four primary dimensions that we commonly use within Endeca to characterize search and discovery contexts. The first dimension is what we call User Type. Now, there are many dimensions of variation along which we could characterise users, but one of the most important is their level of knowledge or expertise. For example, imagine you are designing the search experience for an electronics retail website: are your users likely to be highly knowledgeable tech enthusiasts or uncertain novice shoppers? Likewise, if you were designing the search application for an electronic component supplier: are your users likely to be expert electronics engineers, or purchasing agents with limited domain knowledge?
In each case, the level of knowledge or expertise affects the level of support they are likely to need or appreciate as well as their ability to quickly interpret and sift through volumes of information. The user with the more limited domain knowledge may be more likely to benefit from interactive support in their query formulation, and hence find a feature such as Instant more valuable.

User vary in their level of knowledge and expertise
The second dimension of the search experience is the users’ goal and the scenarios within which he/she strives to achieve that goal. These goals and scenarios can vary on a spectrum from highly specific “known item” searches to more complex and indeterminate exploratory learning and evaluative analyses, etc. On the simple side of this spectrum, “known item” searches such as “I want to find the latest Harry Potter book”, the user knows what he/she is looking for and can articulate it appropriately. Even if the user cannot recall the exact name of the book, a feature such as Instant can help them try different variations to locate the right results.
However, consider a goal such as “I want to find shoes to match my interview suit”. In a case such as this, the user may have an understanding of the sorts of results that would be valuable, but much less of an idea how to articulate a suitable query. Clearly this is a much more complex case, in which keyword queries and Instant results may help establish an initial direction for the enquiry, but are unlikely to provide a complete solution. To adequately fulfil the constraint of matching the suit, some sort of dialogue that supports exploration of the various facets of price, availability, colour, style, brand, etc. is more likely to be effective.
Finally, consider the case where the user’s goal is to “find an affordable entertainment system for our family”. Here, the user’s goal is at a much higher level of abstraction and complexity, and the use of keyword queries alone is unlikely to constitute an effective search and discovery strategy. In this case, the user is hoping to engage in a serendipitous discovery experience that leads to a plausible set of options for consideration; guided not so much by an explicit, known target but reactive to the world of possibilities that that may be presented to them and the trade-offs between them. In this context, rapidly changing and “instantly” available results may be useful at the outset in helping the user gain a general appreciation of the immediate options, but are unlikely to support the thoughtful consideration and evaluation of results required to identify an “entertainment system” that meets a family’s needs.

Goals and scenarios vary in breadth and complexity
The third dimension of the search experience considers the Information Assets that users need to interact with in achieving their goals. In many ways, this dimension and the previous two reflect the classic concerns of user centred design, in which the initial focus is to understand and specify the context of use by identifying “the people who will use the product, what they will use it for, and under what conditions they will use it”.
Clearly, in an information-centric environment, there are many potential factors by which we could characterise such conditions of use, such as social, organisational, environmental, and so on. But one of the most important is the nature of the assets themselves. For example, are they relatively simple, homogeneous records that are human readable and self-describing (such as HTML pages in your native language)? In such cases, the relationship between keyword queries and search results may be quite apparent, and the feedback provided by Instant results can be of clear benefit. But what of cases where the information space is populated by complex, multi-faceted records that act as proxies for real world objects that are only meaningfully understood by their features and characteristics (such as electronic components or assemblies)? In such cases, it is unclear whether Instant results would deliver anything meaningful (except in edge cases such as lookup scenarios where related part numbers arbitrarily share a common prefix, etc.)
Moreover, the information space could be augmented by further meta-information in the form of product reviews, ratings and so on (which are becoming increasingly commonplace in eCommerce environments), or analytics views onto aggregated records (which are typical of enterprise search and business intelligence applications). Again, it is unclear how effective Instant results would be when applied to such complex, heterogeneous information spaces.

Information assets vary in complexity
The fourth dimension of the search experience is what we call the Mode of Interaction. In many ways, this is the hardest of the four to define, as it is essentially an abstraction of the many types of behaviours (or modes) that we commonly observe when studying human information seeking behaviour. As such, it is a fluid concept, with many alternative models and approaches. Donna Spencer, for example defines four Modes of Seeking Information: “Known-Item”, “Exploratory”, “Don’t know what you need to know” and “Re-finding”.
Our own model currently defines ten modes of interaction, and draws on the work on Gary Marchionini in his work on exploratory search. In this he defines three broad categories of search activity: Lookup, Learn, and Investigate. Lookup subsumes the basic tasks of know-item search, fact retrieval, etc., and is the focus for much of what current web search engines support. GI, with its focus on interactive support for query formulation, is of clear benefit for such tasks. By contrast, the Learn and Investigate activities deal with exploratory search, and subsume tasks like comparison, aggregation, analysis, synthesis, evaluation. Evidently, these are complex, iterative behaviours that go beyond mere fact retrieval or lookup, and require a much richer kind of interaction or dialogue between system and end user.
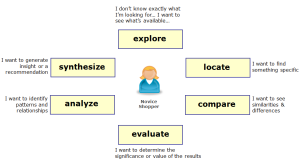
Different mdes of information interaction
In Closing
There’s no doubt that Google Instant is a significant development in the state of the art for web search, not least for the engineering achievement in developing the infrastructure required to deliver such an experience with sub-second response times on vast and diverse sets of information across the web. But the extent to which it will change the way we search really depends on the context of use. At the very least, this should consider the user type, their goals/scenarios, information asset types, and likely modes of interaction. In this context, instantly changing search results can be either instantly helpful or instantly ineffective.
But in many ways, this article really isn’t so much about Instant or any one particular feature of the Google search experience. Instead, it is about establishing a framework by which any feature of the search experience can be meaningfully understood and evaluated; whether it be a part of web search, site search, or enterprise search. In that respect, we are only just beginning to understand the critical dimensions of the human information seeking behaviour and discovery experience, and how to translate that understanding into design principles that help information seekers get beyond “instant” findings to understanding and discovery.
Footnote: this is a revised version of “Is Instant Search Instantly Valuable?” on Search Facets.
Read Full Post »













