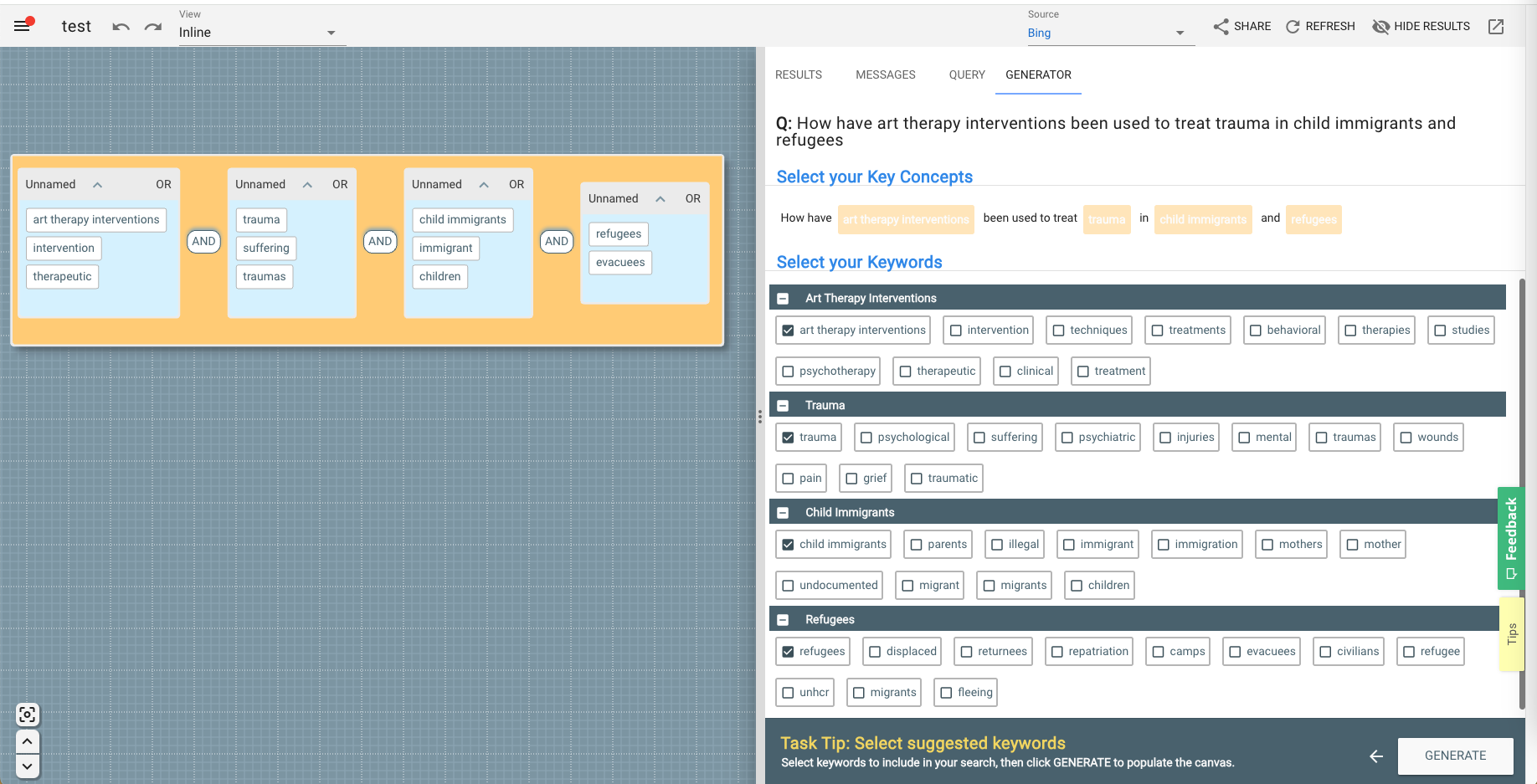
I am delighted to announce a new release of 2Dsearch, which features a new onboarding experience that provides a much more integrated search journey, particularly for new users. Why does this matter? Well, one of things we’ve come to appreciate since conceiving the 2D approach is the potential of that blank canvas, with its limitless possibilities for constructing precise, accurate searches from simple visual components. But that is also its biggest weakness — faced with a blank screen, many people just don’t know where to start.
This release addresses that, with an integrated onboarding experience that offers four clear journeys:
- a blank canvas
- a set of standardised templates (e.g. PICO, SPIDER, etc.)
- a set of curated samples (showing the types of searches that each source supports)
- an AI-powered search strategy generator (which we covered in our last release)
You could say this release merely re-packages what we had before, since each of these features already existed somewhere in the app. But they were buried within separate, unconnected journeys and options. In bringing them together, we now offer an integrated experience that provides the support you need throughout your search journey, whether you are novice user or seasoned expert.
This is particularly good news for students and researchers who don’t always want to spend time formulating a robust, accurate search strategy. Now you can choose how much support you need from the outset. Want it all done for you? Choose the AI option. Want to start from a proven framework? Choose a search template. Want to see what each source offers? Choose a curated sample. And if after all that you prefer the DIY approach, just select a blank canvas.
There’s lots more in this release, including many UX improvements and bug fixes, so we hope you enjoy checking it out. As always, 2Dsearch is free to use for everyone, whether you’re a student/researcher, an information professional or even a recruiter/sourcing professional. We’ve lots more planned for the next release, so if you’d like to help shape this or have comments or suggestions then do let us know. We’d be delighted to hear from you. 2Dsearch